들어가며
https://develop-706.tistory.com/75 지난번 람다에 이은 포스팅입니다.
람다와 함수형 인터페이스는 코드 간결성, 함수형 프로그래밍 지원, 병렬 처리 간소화를 위해 Java 8에서 도입되었습니다. 직접적인 성능 최적화보다는 개발자 생산성 향상과 멀티코어 활용이 주 목적이었습니다.
특히 람다와 함수형 인터페이스는 자바에서 제공하는 강력한 추상화 도구로, 자바 표준 라이브러리와 스프링 프레임워크에서 광범위하게 활용되고 있습니다. 따라서 내부 동작과 과정을 제대로 이해하려면 함수형 인터페이스에 대한 깊은 이해가 필수적이라고 생각하여 포스팅 하게 되었습니다. (학습자에 대한 내용으로, 틀린 내용이 있음을 사전에 전달 드립니다.)
함수형 인터페이스 기본 개념
❓함수형 인터페이스란?
람다를 사용하기 위해서는 정확히 하나의 추상 메서드를 가지는 인터페이스에만 할당이 가능합니다.
이러한 단일 추상 메서드를 줄여서 SAM(Single Abstract Method)이라고 표현하며, 이러한 특징을 가진 인터페이스를 함수형 인터페이스라고 지칭합니다.
왜 함수형 인터페이스만 람다 할당이 가능한가?
아래와 같이 여러 추상메서드를 가진 인터페이스가 있다고 해보겠습니다.
//@FunctionalInterface
public interface NotSAMInterface {
void run();
void go();
}
public class SamMain {
public static void main(String[] args) {
// 컴파일 오류
NotSamInterface notSamInterface = () -> {
System.out.println("not sam");
};
notSamInterface.run(); // ?
notSamInterface.go(); // ?
}
}위와 같이 여러개의 추상메서드가 구현되어 있을 때, 모든 메서드에 대해서 @Override(재정의)를 해줘야 합니다.
람다는 하나의 메서드가 보장되고, 그에 대해 재정의 하려는 의도로 만든 것인데, SAM이 준수되지 않는 곳에선 이를 사용할 수 없습니다.
@FunctionalInterface 어노테이션을 붙여줌으로써 SAM을 보장하고 함수형 인터페이스임을 명시할 수 있습니다.

람다의 대입
람다도 결국, 하나의 주소값을 가지는 인스턴스입니다. (람다 객체)
따라서, 다양한 대입이 가능합니다.
1.람다 변수 대입
@FunctionalInterface
public interface MyFunction{
int apply(int a, int b);
}
import lambda.MyFunction;
// 1. 람다를 변수에 대입하기
public class LambdaPassMain1 {
public static void main(String[] args) {
MyFunction add = (a, b) -> a + b; // 1. 람다 인스턴스 생성 (x001)
MyFunction sub = (a, b) -> a - b; // 1. 람다 인스턴스 생성 (x002)
System.out.println("add.apply(1, 2) = " + add.apply(1, 2)); //2. 인스턴스 메서드 실행
System.out.println("sub.apply(1, 2) = " + sub.apply(1, 2)); //2. 인스턴스 메서드 실행
MyFunction cal = add; // 3. 변수 대입 가능 (x001 참조값 대입)
System.out.println("cal(add).apply(1, 2) = " + cal.apply(1, 2));
cal = sub; // 4. 변수 대입 (x002 참조값 대입)
System.out.println("cal(sub).apply(1, 2) = " + cal.apply(1, 2));
}
}
익명클래스를 떠올려보면 쉽습니다! 즉, 하나의 구현체가 돌아다닌다고 생각하면 됩니다.
2.메서드 람다 전달
이번엔 람다를 메서드(함수)에 전달해보겠습니다.
calculate() 메서드의 매개변수는 함수형 인터페이스이기 때문에 람다를 인자로 받을 수 있습니다.
import lambda.MyFunction;
public class LambdaPassMain2 {
public static void main(String[] args) {
MyFunction add = (a, b) -> a + b; // 람다 인스턴스 생성 x001
MyFunction sub = (a, b) -> a - b; // 람다 인스턴스 생성 x002
System.out.println("변수를 통해 전달");
calculate(add); // x001 참조값 전달
calculate(sub); // x002 참조값 전달
System.out.println("람다를 직접 전달");
calculate((a, b) -> a + b); // 직접 x001 참조값 전달
calculate((a, b) -> a - b); // 직접 x002 참조값 전달
}
static void calculate(MyFunction function) { // 매개변수에 참조값 대입
int a = 1;
int b = 2;
System.out.println("계산 시작");
int result = function.apply(a, b); // 전달받은 참조값(x001,x002) 메서드 실행
System.out.println("계산 결과: " + result);
}
}
3.람다 리턴
마지막으로 getOperation() 메서드는 반환 타입이 함수형 인터페이스이기 때문에, 람다를 반환할 수 있습니다.
public class LambdaPassMain3 {
public static void main(String[] args) {
MyFunction add = getOperation("add");
System.out.println("add.apply(1, 2) = " + add.apply(1, 2)); //x001 메서드 실행
MyFunction sub = getOperation("sub");
System.out.println("sub.apply(1, 2) = " + sub.apply(1, 2)); //x002 실행
MyFunction xxx = getOperation("xxx");
System.out.println("xxx.apply(1, 2) = " + xxx.apply(1, 2)); //x003 실행
}
// 람다를 반환하는 메서드
static MyFunction getOperation(String operator) {
switch (operator) {
case "add":
return (a, b) -> a + b; //x001
case "sub":
return (a, b) -> a - b; //x002
default:
return (a, b) -> 0; //x003
}
}
}
함수형 인터페이스를 제대로 알아보자
문제 상황
아래의 코드를 살펴봅시다.
public class Main {
public static void main(String[] args) {
StringFunction upperCase = s -> s.toUpperCase();
String result1 = upperCase.apply("hello");
System.out.println("result1 = " + result1);
NumberFunction square = n -> n * n;
Integer result2 = square.apply(3);
System.out.println("result2 = "+result2);
}
}
@FunctionalInterface
interface StringFunction {
String apply(String s);
}
@FunctionalInterface
interface NumberFunction {
Integer apply(Integer s);
}
각 XXXFunction이 제공하는 추상메서드는 둘 다 하나의 인자를 입력받고, 결과를 반환합니다.
오직 입력받는 타입과 반환 타입만 다를 뿐입니다. 이렇게 매개변수나 반환 타입이 다를 때마다 계속 함수형 인터페이스를 만들어야 할까요?
어떻게 이런 불필요한 코드 중복을 해결할 수 있을까요?
해결 방법 1: Object 사용 (50점)
첫 번째 방법은 모든 객체의 부모격인 Object 형으로 받는 방법입니다.
public class Main {
public static void main(String[] args) {
ObjectFunction upperCase = s -> ((String)s).toUpperCase(); // 람다 + 다운캐스팅
String result1 = (String) upperCase.apply("hello");
System.out.println("result1 = " + result1);
ObjectFunction square = n -> (Integer) n * (Integer) n; // 람다 + 다운캐스팅
Integer result2 = (Integer) square.apply(3);
System.out.println("result2 = " + result2);
}
@FunctionalInterface
interface ObjectFunction {
Object apply(Object s);
}
}
이렇게 Object와 다형성을 활용한 덕분에 코드의 중복을 제거하고, 재사용성을 늘릴 수 있게 되었습니다.
하지만 Object를 사용함으로써 다운캐스팅을 진행해야하며, 타입 안전성의 문제가 발생하게 됩니다.
다운캐스팅을 강제 했을때의 문제는 컴파일 시점에는 오류가 발생하지 않지만, 실행 시점에 타입이 맞지 않으면 ClassCastException이 발생한다는 점입니다.
해결 방법 2: 제네릭 사용 (100점)
두 번째 방법은 바로 제네릭 기법을 사용하는 방식입니다.
실제로 해당 제네릭 기법이 가장 권장됩니다
public class Main {
public static void main(String[] args) {
GenericFunction<String, String> upperCase = s -> s.toUpperCase();
String result1 = upperCase.apply("hello");
System.out.println("result1 = " + result1);
GenericFunction<Integer, Integer> square = n -> n * n;
Integer result2 = square.apply(3);
System.out.println("result2 = " + result2);
}
@FunctionalInterface
interface GenericFunction<T, R> { //제네릭 사용
R apply(T s);
}
}
제네릭을 도입함으로써 타입추론이 가능하기 때문에, 코드 재사용도 늘리고 타입 안전성까지 높일 수 있습니다.
일일히 개발자가 함수형 인터페이스를 정의해주어야 하는가?
다음과 같은 여러 기능이 내포되어 있는 프로젝트가 있다고 가정 해봅시다.
개발자 A는 본인 영역의 util 패키지 내에 함수형 인터페이스를 하나 정의했습니다.
@FunctionalInterface
interface FunctionA {
String apply(Integer i);
}
개발자 B 또한 본인만의 util 패키지 내에 함수형 인터페이스를 정의했습니다.
@FunctionalInterface
interface FunctionB {
String apply(Integer i);
}
안에 내부 코드와 동작과정이 모두 동일합니다. 아래의 코드는 어떤 문제가 될까요?
public class Main {
public static void main(String[] args) {
// 람다 직접 대입: 문제 없음
FunctionA aFunc = i -> "value = " + i;
FunctionB bFunc = i -> "value = " + i;
FunctionA targetA = aFunc;
FunctionB targetB = aFunc; //컴파일 오류가 난다.
}
}
꽤나 당연하게도, FunctionB targetB = aFunc를 하는 과정에서 컴파일 에러가 발생합니다. 두 개의 타입이 다르기 때문에, 서로간 대입을 할 수 없기 때문입니다.
이렇듯, 함수형 인터페이스를 개발자가 직접 모두 만들어버리게 되면, 같은 내부 코드와 의도를 가짐에도 불구하고 서로간의 충돌이 발생할 위험이 있습니다.
✅자바가 기본으로 제공하는 함수형 인터페이스
자바는 이런 문제들을 해결하기 위해 필요한 함수형 인터페이스 대부분을 기본으로 제공합니다.
개발자가 정말 특별한 목적이 있지 않는 한, 함수형 인터페이스를 직접 정의해서 쓰기보다는 자바가 제공하는 함수형 인터페이스를 사용하는것이 권장됩니다.
자바가 제공하는 함수형 인터페이스를 사용하면, 비슷한 함수형 인터페이스를 불필요하게 만드는 문제는 물론이고, 함수형 인터페이스의 호환성 문제까지 해결할 수 있습니다.
자바가 제공하는 대표적인 함수형 인터페이스 4가지
인터페이스 메서드 시그니처 입력 출력 대표 사용 예시
| Function<T, R> | R apply(T t) | 1개 (T) | 1개 (R) | 데이터 변환, 필드 추출 등 |
| Consumer<T> | void accept(T t) | 1개 (T) | 없음 | 로그 출력, DB 저장 등 |
| Supplier<T> | T get() | 없음 | 1개 (T) | 객체 생성, 값 반환 등 |
| Runnable | void run() | 없음 | 없음 | 스레드 실행(멀티스레드) |
1.Function: 입력 O, 반환 O
- Function은 수학적인 "함수" 개념을 그대로 반영한 이름입니다.
- 하나의 매개변수를 받고, 결과를 반환하는 함수형 인터페이스입니다.
- apply는 "적용하다"라는 의미로, 입력값에 함수를 적용해서 결과를 얻는다는 수학적 개념을 표현합니다.
예: f(x)처럼 입력 x에 함수 f를 적용(apply)하여 결과를 얻는다.

예시:
public class FunctionMain {
public static void main(String[] args) {
// 익명 클래스
Function<String, Integer> function1 = new Function<>() {
@Override
public Integer apply(String s) {
return s.length();
}
};
System.out.println("function1 = " + function1.apply("hello"));
// 람다
Function<String, Integer> function2 = s -> s.length();
System.out.println("function2 = " + function2.apply("hello"));
}
}
2. Consumer: 입력 O, 반환 X
- Consumer는 "소비자"라는 의미로, 데이터를 받아서 소비(사용)만 하고 아무것도 돌려주지 않는다는 개념을 표현합니다.
- 입력 값(T)만 받고, 결과를 반환하지 않는 void 연산을 수행하는 함수형 인터페이스입니다.
- accept는 "받아들이다"라는 의미로, 입력값을 받아들여서 처리한다는 동작을 설명합니다.
- 입력 받은 데이터를 기반으로 내부적으로 처리만 하는 경우에 유용합니다.
예: 컬렉션에 값 추가, 콘솔 출력, 로그 작성, DB 저장 등
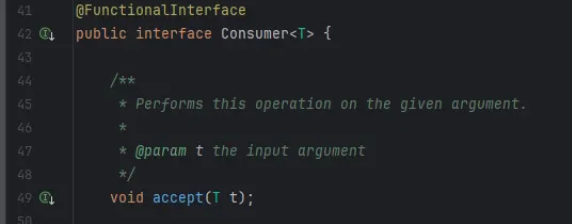
예시:
public class ConsumerMain {
public static void main(String[] args) {
// 익명 클래스
Consumer<String> consumer1 = new Consumer<>() {
@Override
public void accept(String s) {
System.out.println(s);
}
};
consumer1.accept("hello consumer");
// 람다
Consumer<String> consumer2 = (s) -> System.out.println(s);
consumer2.accept("hello consumer");
}
}
3. Supplier: 입력 X, 반환 O
- Supplier는 "공급자"라는 의미로, 요청할 때마다 값을 공급해주는 역할을 합니다.
- 입력을 받지 않고, 어떤 데이터를 공급(supply)해주는 함수형 인터페이스입니다.
- get은 "얻다"라는 의미로, supplier로부터 값을 얻어온다는 개념을 표현합니다.
- 객체나 값의 생성, 지연 초기화 등에 주로 사용됩니다.
예: 랜덤 값을 제공하는 supplier는 호출할 때마다 새로운 랜덤 값을 공급합니다.

예시:
public class SupplierMain {
public static void main(String[] args) {
// 익명 클래스
Supplier<Integer> supplier1 = new Supplier<Integer>() {
@Override
public Integer get() {
return new Random().nextInt(10);
}
};
System.out.println("supplier1.get() = " + supplier1.get());
// 람다
Supplier<Integer> supplier2 = () -> new Random().nextInt(10);
System.out.println("supplier2.get() = " + supplier2.get());
}
}
4. Runnable: 입력 X, 반환 X
- 입력값도 없고 반환값도 없는 함수형 인터페이스입니다.
- 자바에서는 원래부터 스레드 실행을 위한 인터페이스로 쓰였지만, 자바 8 이후에는 람다식으로도 많이 표현됩니다.
- 자바8로 업데이트되면서 @FunctionalInterface 어노테이션도 붙었습니다.
- java.lang 패키지에 있습니다. 자바의 경우 원래부터 있던 인터페이스는 하위 호환을 위해 그대로 유지합니다.
- 주로 멀티스레딩에서 스레드의 작업을 정의할 때 사용합니다.

✅특화 함수형 인터페이스
특화 함수형 인터페이스는 의도를 명확하게 만든 조금 특별한 함수형 인터페이스입니다.
해당 인터페이스는 정말 확실한 "용도"가 있기 때문에 해당 함수형 인터페이스를 가져다 쓴다는 것은 정말 명확한 의도가 있다는 것을 의미합니다.
| Predicate<T> | boolean test(T t) | 1개 (T) | boolean | 조건 검사, 필터링 |
| UnaryOperator<T> | T apply(T t) | 1개 (T) | 1개 (T; 입력과 동일) | 단항 연산 (예: 문자열 변환, 단항 계산) |
| BinaryOperator<T> | T apply(T t1, T t2) | 2개 (T, T) | 1개 (T; 입력과 동일) | 이항 연산 (예: 두 수의 합, 최댓값 반환) |
1. Predicate: 입력 O, 반환 boolean
- Predicate는 수학/논리학에서 "술어"를 의미하며, 참/거짓을 판별하는 명제를 표현합니다.
- 입력 값(T)을 받아서 true 또는 false로 구분(판단)하는 함수형 인터페이스입니다.
- test는 "시험하다"라는 의미로, 주어진 입력값이 조건을 만족하는지 테스트한다는 의미입니다. 그래서 반환값이 boolean입니다.
- 조건 검사, 필터링 등의 용도로 많이 사용됩니다. 특히 스트림 API에서 필터 조건을 지정할 때 자주 등장합니다.
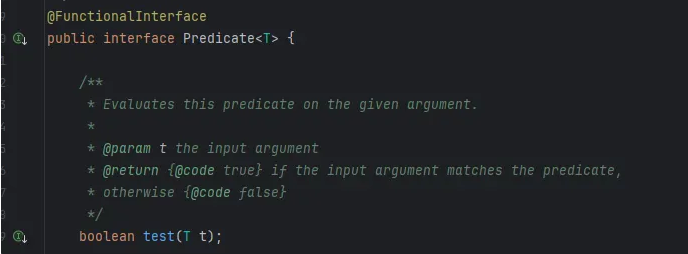
스트림 API에서 필터 조건을 지정할 때 사용 예시:
public class PredicateExample {
public static void main(String[] args) {
List<String> names = List.of("Alice", "Bob", "Charlie", "David");
// 이름이 5글자 이상인 것만 필터링
List<String> result = names.stream()
.filter(name -> name.length() >= 5) // <- 내부적으로 Predicate 사용
.collect(Collectors.toList());
System.out.println(result); // [Alice, Charlie, David]
}
}
일반 예시:
public class PredicateMain {
public static void main(String[] args) {
Predicate<Integer> predicate1 = new Predicate<>() {
@Override
public boolean test(Integer value) {
return value % 2 == 0;
}
};
System.out.println("predicate1.test(10) = " + predicate1.test(10));
Predicate<Integer> predicate2 = value -> value % 2 == 0;
System.out.println("predicate2.test(10) = " + predicate2.test(10));
}
}
Predicate가 꼭 필요할까?
Predicate는 입력이 T, 반환이 boolean이기 때문에 사실 Function<T, Boolean>과 다를 바가 없습니다.
그럼에도 불구하고 Predicate를 별도로 만든 이유는 true/false로 결과를 판단한다는 의도를 명시적으로 드러내기 위해 정의된 함수형 인터페이스입니다.
💡 영한왈: 자바가 제공하는 다양한 함수형 인터페이스들을 선택할 때는 단순히 입력값, 반환값만 보고 선택하는 게 아니라 해당 함수형 인터페이스가 제공하는 의도가 중요합니다.
예를 들어서 조건 검사, 필터링 등을 사용한다면 Function이 아니라 Predicate를 선택해야 합니다. 그래야 다른 개발자가 "아~ 이 코드는 조건 검사 등에 사용할 의도가 있구나" 하고 코드를 더욱 쉽게 이해할 수 있습니다.
2. UnaryOperator: 입력 O, 반환 O (동일 타입, 입력 1개)
단항 연산 → 한 개의 입력과 결과가 동일한 타입으로 연산을 수행할 때 사용
- 예: 숫자 5를 입력하고 그 수를 제곱한 결과를 반환
- 예: String으로 입력받아 대문자로 치환해서 반환, 앞뒤에 문자열 추가 등
Function<T, T>를 상속받는데, 같은 T로 고정합니다. 따라서 입력타입과 반환타입은 같은 타입으로 강제됩니다.
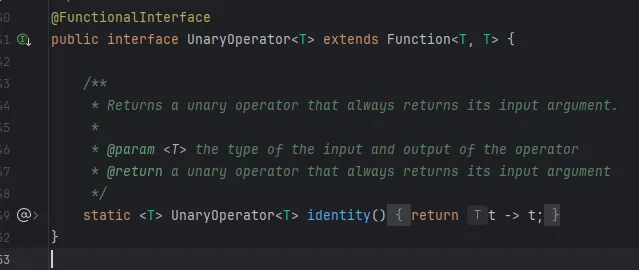
3. BinaryOperator: 입력 O, 반환 O (동일타입, 입력 2개)
이항 연산 → 두 개의 입력에 대해 연산을 수행할 때 사용
- 예: x + y, x * y 등
- 예: Integer 두 개를 받아서 더한 값을 반환
- 예: Integer 두 개를 받아서 둘 중 더 큰 값을 반환
BiFunction<T, T, T>를 상속받는데, 모두 같은 T로 고정합니다. 따라서 두 개의 입력타입과 반환 타입은 같은 타입으로 강제됩니다.
특히 스트림 API에서 reduce()를 할 때 사용됩니다.

스트림 API에서 reduce()를 할 때 사용 예시:
Stream<Integer> numbers = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
Optional<Integer> sum = numbers.reduce((x, y) -> x + y);
sum.ifPresent(s -> System.out.println("sum: " + s));
Output:
sum: 55
위의 예제를 살펴보면 reduce() 의 동작 방식에 대해서 소개하겠습니다.
마치며
이상으로 함수형 인터페이스에 대해 알아보았습니다.
함수형 인터페이스를 직접 구현하여 사용 할 일은 많지 않겠지만, 내부 문서와 라이브러리를 살펴볼 때. 그리고 Stream 을 사용할 때 유용하게 쓰일 것이라 생각합니다.
이상, 함수형 인터페이스를 마치겠습니다. 감사합니다 :)